SQL에서는 데이터를 정렬한 후 순위를 매길 때 RANK()와 DENSE_RANK()를 사용합니다.
이 함수들은 **윈도우 함수(Window Function)**로 OVER() 절과 함께 사용됩니다.
✅ 1. RANK() 함수
RANK() 함수는 순위를 매길 때 **동일한 값(타이)**이 있으면 같은 순위를 부여하고,
그 다음 순위는 이전 순위 + 중복 개수를 반영하여 건너뜁니다.
📌 예제 1: 직원의 급여 순위 출력 (RANK 사용)
SELECT employee_id, name, salary,
RANK() OVER (ORDER BY salary DESC) AS rank
FROM employees;
📌 실행 결과

설명:
- 이순신과 강감찬은 같은 급여(8,000,000)를 받으므로 동일 순위(2위)
- 다음 순위는 3이 아니라 4위로 건너뜀 (2위가 2명 → 다음 순위 = 4)
✅ 2. DENSE_RANK() 함수
DENSE_RANK() 함수는 RANK()와 비슷하지만,
순위를 건너뛰지 않고 연속된 값으로 부여합니다.
📌 예제 2: 직원의 급여 순위 출력 (DENSE_RANK 사용)
SELECT employee_id, name, salary,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM employees;
📌 실행 결과
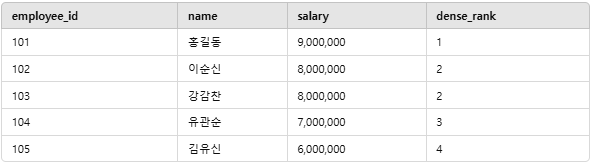
설명:
- 이순신과 강감찬은 같은 급여(8,000,000) → 동일 순위(2위)
- 다음 순위는 3위(연속됨)
✅ 3. RANK() vs DENSE_RANK() 비교
| 이름 | 순위 방식 |
| RANK() | 동일한 순위가 있으면 건너뛰고 다음 순위 배정 |
| DENSE_RANK() | 동일한 순위가 있어도 건너뛰지 않고 연속된 순위 부여 |
📌 예제 데이터 적용 비교
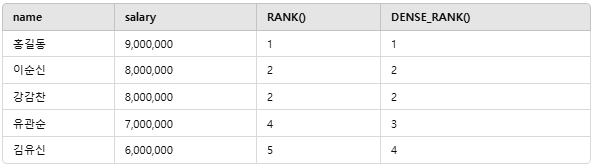
✅ 4. PARTITION BY로 그룹별 순위 매기기
PARTITION BY를 사용하면 부서별, 지역별 등 그룹별로 순위를 매길 수 있음
📌 예제 3: 부서별 급여 순위 출력
SELECT department, employee_id, name, salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;
📌 실행 결과

설명:
- PARTITION BY department → 부서별로 그룹을 나눈 후 순위 매김
- 각 부서 내에서 급여 내림차순(ORDER BY salary DESC) 순위 부여
✅ 5. 정리
✅ RANK() → 동일 순위가 존재하면 순위를 건너뛰고 다음 순위 부여
✅ DENSE_RANK() → 동일 순위가 존재해도 순위를 연속적으로 부여
✅ PARTITION BY를 사용하면 그룹(부서, 지역 등)별 순위 계산 가능
'기획자가 알아야 할 IT지식 > 기획자가 알아야 할 SQL' 카테고리의 다른 글
| 25강. 누적 합계 구하기 (SUM OVER 함수) (0) | 2025.03.24 |
|---|---|
| 24강. 그룹을 나누어 순위를 매기기 (NTILE 함수) (0) | 2025.03.24 |
| 22강. SQL에서 합계 및 개수 구하기 (SUM, COUNT) (0) | 2025.03.24 |
| 21강. SQL에서 최대, 최소, 평균값 구하기 (MAX, MIN, AVG) (0) | 2025.03.23 |
| 20강. 조건에 따라 다른 값을 반환하는 CASE WHEN 문 (0) | 2025.03.23 |



